The Architecture of Large Language Models: how they're built and why it matters

Sai come vengono costruiti i LLM? Facciamoci un’idea.
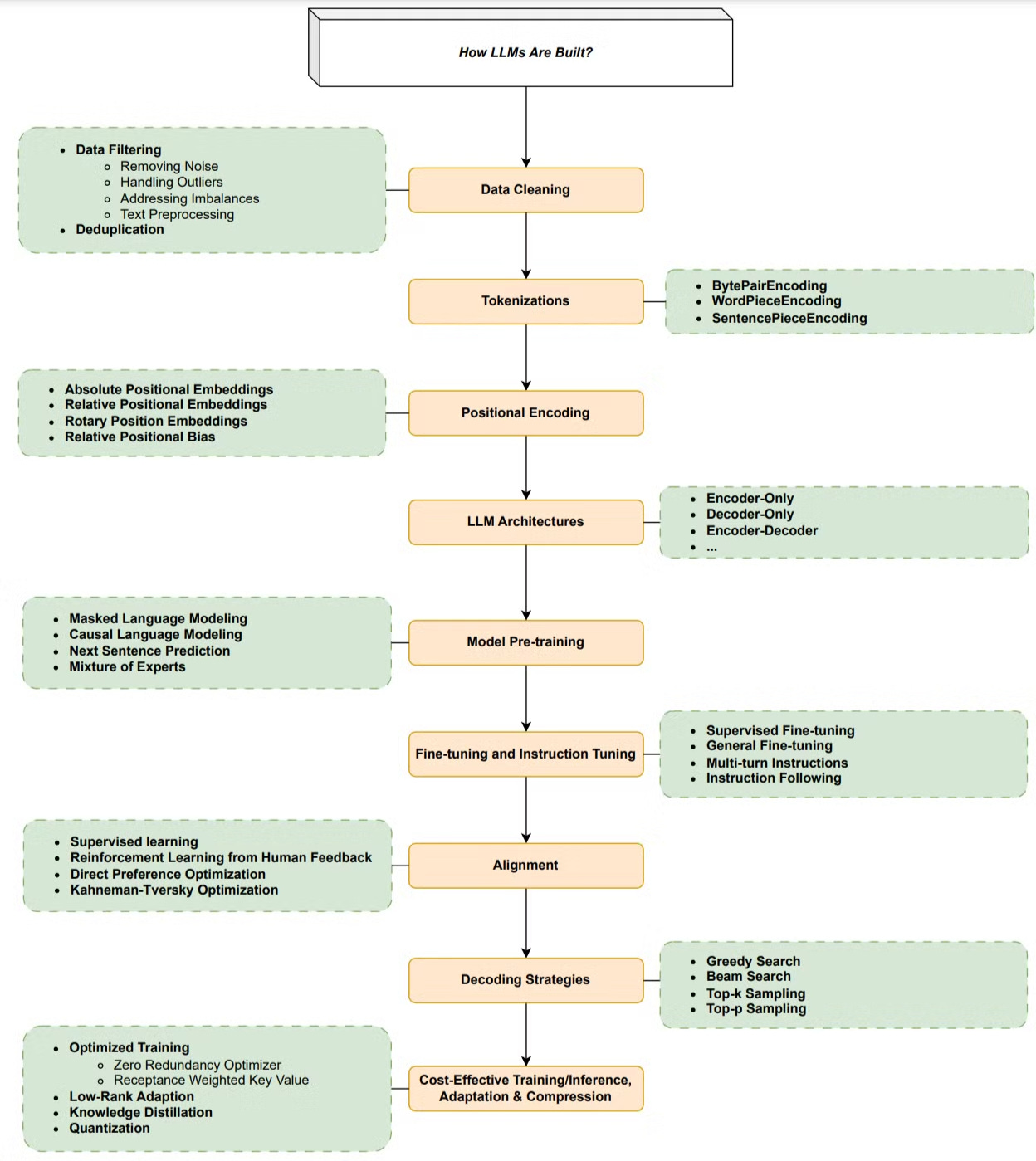
Una volta scelta l’architettura del modello, le fasi principali dell’addestramento di un LLM includono:
Preparazione dei dati (raccolta, pulizia, deduplicazione, ecc.)
Tokenizzazione
Pre-training del modello (in modalità di apprendimento auto-supervisionato)
Instruction tuning
Allineamento
Preparazione dei Dati
La qualità dei dati è cruciale per le prestazioni dei modelli linguistici che vi vengono addestrati sopra. Tecniche di pulizia dei dati, come il filtraggio, hanno dimostrato di avere un impatto significativo sulle performance del modello.
Tokenizzazione
La tokenizzazione è il processo che converte una sequenza di testo in parti più piccole chiamate token. Mentre i metodi più semplici dividono il testo in base agli spazi, la maggior parte degli strumenti di tokenizzazione si basa su un dizionario di parole o sub-parole.
Codifica Posizionale
Le Absolute Positional Embeddings sono state usate nel modello Transformer originale per conservare l’informazione sull’ordine delle parole nella sequenza. L’informazione posizionale viene quindi aggiunta agli input embeddings alla base sia dello stack dell’encoder che di quello del decoder.
Esistono varie opzioni per la codifica posizionale, sia fisse che apprese.
Architetture degli LLM
Le architetture più diffuse per i Large Language Models sono:
Encoder-only
Decoder-only
Encoder-decoder
La maggior parte di esse si basa sul Transformer come building block fondamentale.
Pre-training del Modello
Il pre-training è il primo passo nella pipeline di addestramento dei grandi modelli linguistici. Serve a dotare gli LLM di una comprensione generale del linguaggio, utile per una vasta gamma di compiti linguistici.
Durante questa fase, il modello viene addestrato su enormi quantità di testo (solitamente non etichettato), in modalità auto-supervisionata.
Fine-tuning e Instruction Tuning
I primi modelli linguistici, come BERT, venivano addestrati con auto-supervisione. Per renderli utili, era necessario un fine-tuning supervisionato su compiti specifici con dati etichettati (Supervised Fine Tuning, o SFT).
Ad esempio, nel paper originale di BERT, il modello venne riaddestrato su 11 task differenti.
I modelli più recenti, invece, possono essere utilizzati senza fine-tuning specifico, anche se continuano a trarne vantaggio in caso di compiti o dataset particolari.
Ci sono poi altri parametri importanti da considerare, come l’allineamento (alignment), le strategie di decodifica, e altro ancora.
Per approfondire il tema e accedere all’immagine completa, puoi leggere questo paper di ricerca:
👉 https://arxiv.org/pdf/2402.06196