
𝗟’𝗔𝗜 𝗲 𝗽𝗶𝘂 𝘀𝗶𝗰𝘂𝗿𝗮 𝗱𝗲𝗶 𝗺𝗲𝗱𝗶𝗰𝗶. ”𝗦𝗮𝗿𝗮’ 𝗾𝘂𝗲𝘀𝘁𝗼 𝗶𝗹 𝘁𝗶𝘁𝗼𝗹𝗼. 𝗘𝗱 𝗲’ 𝗳𝘂𝗼𝗿𝘃𝗶𝗮𝗻𝘁𝗲.

Il preprint NOHARM (”towards clinically safe large language models”) è uno studio serio, fatto da clinici che conoscono bene sia la medicina sia i limiti dell’AI. L’obiettivo non era dimostrare che l’AI “batte” i medici, ma capire quali LLM possano aiutare senza fare danni.
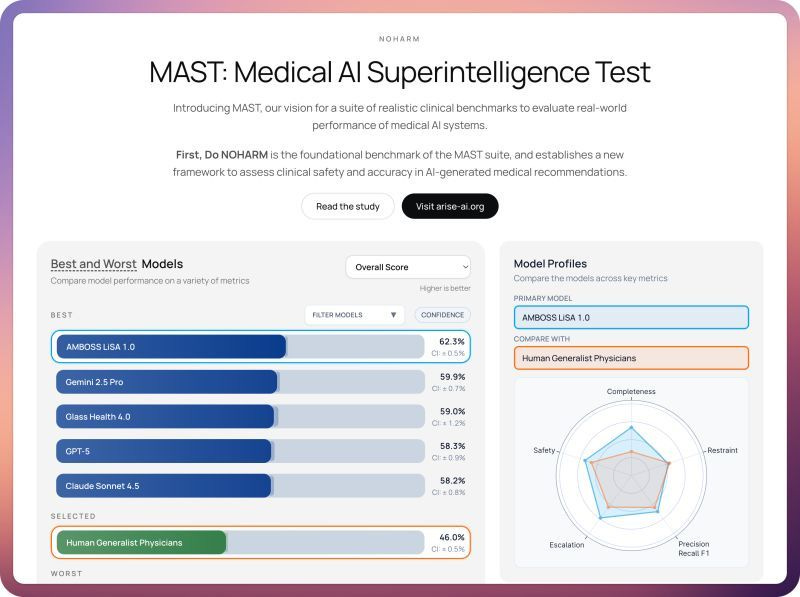
Sono stati testati 31 modelli su casi clinici reali provenienti dal servizio di eConsult di Stanford. Non domande teoriche: i modelli dovevano scegliere tra molte opzioni di gestione, selezionando quelle corrette ed evitando quelle inappropriate. Lo stesso test è stato sostenuto anche da medici.
𝗣𝘂𝗻𝘁𝗼 𝗰𝗵𝗶𝗮𝘃𝗲 𝗰𝗵𝗲 𝗺𝗼𝗹𝘁𝗶 𝗶𝗴𝗻𝗼𝗿𝗲𝗿𝗮𝗻𝗻𝗼:
questi non sono casi di pratica clinica ordinaria.
Le eConsult riguardano situazioni al limite della conoscenza del singolo clinico, i casi “grigi”, quelli per cui si chiede supporto specialistico.
𝗜 𝗿𝗶𝘀𝘂𝗹𝘁𝗮𝘁𝗶?
Gli LLM commettono errori con potenziale danno, soprattutto per omissione, talvolta severi. I migliori modelli superano i medici, ma in media le performance sono comparabili.
𝗟𝗮 𝗹𝗲𝘁𝘁𝘂𝗿𝗮 𝗰𝗼𝗿𝗿𝗲𝘁𝘁𝗮 𝗲’ 𝗾𝘂𝗲𝘀𝘁𝗮:
Non “AI vs medici”, ma AI come supporto nei casi complessi, proprio dove anche il medico esperto sa di aver bisogno di aiuto.
Nella pratica reale, i medici gestiscono correttamente la grande maggioranza dei casi. Qui stiamo osservando quella piccola ma critica frazione in cui il supporto decisionale ha davvero senso.
Il paper è ricco (interessante anche la parte sui modelli collaborativi) e merita una lettura attenta.
📊Leaderboard: https://bench.arise-ai.org/
👉Preprint: https://arxiv.org/pdf/2512.01241